


Footnotes
- As it can be seen in this link, 9,268 of Mr. Kinkade's graphic works are included in the LAION database, used to train the Stable Diffusion AI model.
- The Writers Guild of America strike and the EGAIR manifesto are good examples of this.
- Terminologically, we use "AI model" when we refer to the back-end, i.e., the AI engine. On the other hand, we use "AI system" when we want to refer to the whole application. This difference is clear in the wording of Article 10.6 of the AI ACT, which uses both terms in this sense.
- As explained in the article "What exactly is Machine Learning?”
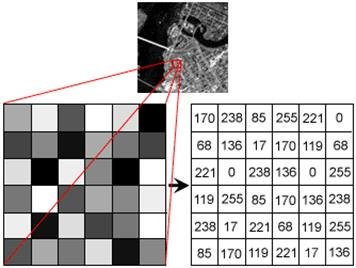
- Figure extracted from here. Evidently, the process is much more complex than the example.
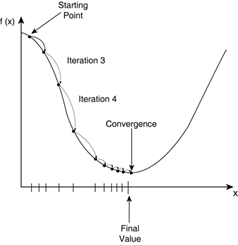
- Strictly speaking, when calculating the error of a single output we would be talking about the loss function, which becomes the cost function when what it expresses is the average error of the training performed as a whole.
- Considering that the values of the AI model start out being random.
- Graphic obtained from this website.
- Titled "But what is a neural network? | Chapter 1, Deep learning" and "Gradient descent, how neural networks learn | Chapter 2, Deep learning" both from the channel "3Blue1Brown".
- See definition of "reasoning" from the Oxford Dictionary.
- As the articles "What Is Stable Diffusion and How Does It Work?" and "How does Stable Diffusion work?" explain in more technical detail.
- A highly complex concept, as explained in the article "What Is the Latent Space of an Image Synthesis System?”
- Image from the aforementioned article "How does Stable Diffusion work?".
- Gif extracted from Reddit, Here's a short video of what happens behind the scenes when Stable Diffusion generates a picture.
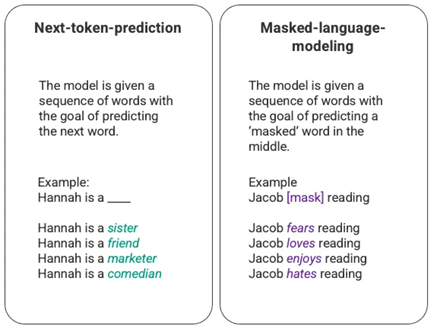
- Although it may not be entirely accurate, it is an understandable concept. To see more, check out the articles "How ChatGPT Works: The Model Behind The Bot" and "How ChatGPT actually works".
- This is not a panacea either. See the (rather outdated but not negligible) article “How to Systematically Fool an Image Recognition Neural Network" on how to fool such a system.
- In favor, and explaining it better than us, the excellent paper “Fair Learning". Against, Stable Diffusion litigation argues that the output should be considered a derivative work of the works used to train the model. Suffice it for now to point out that to state that a given work generated by an AI model is a derivation of the previous works with which the model has been trained (which may well be more than a million even for the least popular images) is to distort the concept of derivative work.
- Titled "Generative AI, Copyright and the AI Act" by João Pedro Quintais.
- In paragraph 62 of the CJEU Decision "Infopaq I" (ECLI:EU:C:2009:465), with regard to the provisional nature of the reproduction, it is held that:Legal certainty for rightholders further requires that the storage and deletion of the reproduction not be dependent on discretionary human intervention, particularly by the user of protected works. There is no guarantee that in such cases the person concerned will actually delete the reproduction created or, in any event, that he will delete it once its existence is no longer justified by its function of enabling the completion of a technological process." Therefore, if the deletion of the original works is automatic when they are replaced by patterns (in fact, it should be, since the AI models lack sufficient memory to store the original images), their use must be considered to be temporary.
- This is extremely relevant in view of paragraph 65 of the aforementioned CJEU Decision Infopaq IThat is, if the owner of an AI decides to maintain a repository with the works used to train the AI for any reason (traceability of the system, data protection, image rights management, model bias reviews, etc.), the exception will no longer apply. It seems that, undesirably, good practice such as this in AI model training is penalized. Likewise, the Spanish Supreme Court has emphasized this issue in Judgment 650/2022 of October 11 (ECLI:ES:TS:2022:3598): “the defendant should have justified that the reproduction of those phonograms aimed at their public communication was part of a technological process that ensured the provisional and transitory nature of the reproduction by means of an automated mechanism that, both in its creation and suppressiondoes not require human intervention."
- CJUE Decision "Stichting Brein" C-527/15 of 26 April 2017 (ECLI:EU:C:2017:300).
- CJUE Decision Football Association Premier League and others, C-403/08 and C-429/08, of 4 October 2011 (ECLI:EU:C:2011:631), § 170-172.
- Sensu contrario, the CJUE Decision "Ryanair" Case C-30/14 (ECLI:EU:C:2015:10) is applicable, since the content subject to scraping is subject to copyright protection, the exception of the Infosoc Directive that we are now analyzing will apply to the scraping itself. To contextualize, scraping is something that Google does regularly to have indexed all possible internet content in its search engine, which it will access unless the owner of the website "opts-out" with technological measures.
- Pablo Fernández Carballo-Calero, in his work "La propiedad intelectual de las obras creadas por inteligencia artificial" analyzes whether intellectual property should encourage content generated by an AI without human intervention according to the theories 1) Of work (Locke) 2) Personalist and 3) Utilitarian. The conclusion reached is that the spirit of copyright should not lead us to recognize as works those created without human intervention. However, this does not mean that such generation is an illicit activity, but simply that it should not be encouraged through intellectual property.
- I'm running out of ways to say "lots and lots of data".
- This analysis is made without losing sight of the fact that the CJEU, in Infopaq II, paragraphs 55-57 says: "suffice it to note that if those acts of reproduction fulfil all the conditions of Article 5(1) of Directive 2001/29, as interpreted by the case-law of the Court, it must be held that they do not conflict with the normal exploitation of the work or unreasonably prejudice the legitimate interests of the rightholder". Despite the conclusive words of the CJEU this reasoning does not seem applicable without further reflection to ML cases.
- Available at this link: “It is permissible to exploit a work, in any way and to the extent considered necessary, in any of the following cases, or in any other case in which it is not a person's purpose to personally enjoy or cause another person to enjoy the thoughts or sentiments expressed in that work; provided, however, that this does not apply if the action would unreasonably prejudice the interests of the copyright owner in light of the nature or purpose of the work or the circumstances of its exploitation: (i) if it is done for use in testing to develop or put into practical use technology that is connected with the recording of sounds or visuals of a work or other such exploitation; (ii) if it is done for use in data analysis (meaning the extraction, comparison,classification, or other statistical analysis of the constituent language, sounds, im-ages, or other elemental data from a large number of works or a large volume of other such data; the same applies in Article 47-5, paragraph (1), item (ii));(iii) if it is exploited in the course of computer data processing or otherwise exploited in a way that does not involve what is expressed in the work being per-ceived by the human senses (for works of computer programming, such exploitation excludes the execution of the work on a computer), beyond as set forth in the preceding two items.”
- As stated in the exceptional article: Text and data mining exceptions in the development of generative AI models: What the EU member states could learn from the Japanese “nonenjoyment” purposes? by Artha Dermawan.
- As Ryan Khurana describes in this link and as we can we can check in section 2 of the Open AI Terms of Use, among others.
- As eloquently described in “Fair Learning”: “And because training sets are likely to contain millions of different works with thousands of different owners, there is no plausible option simply to license all of the underlying photographs, videos, audio files, or texts for the new use. So allowing a copyright claim is tantamount to saying, not that copyright owners will get paid, but that the use won’t be permitted at all, at least without legislative intervention” .
- As happened to programmer Tim Davis, which he complained about on Twitter.
- As when an AI system produces output that includes copyrighted characters, as in this case. In this case it is a derivative work because the original work is obviously being transformed. However, this is the exception to the general rule, since, as we have seen, the generation of content is not based directly on one or several previous works, but on millions of them, the influence of each one on the final result being imperceptible.
- I'm not afraid of erring on the side of romanticism in thinking that an AI model is never going to be able to faithfully capture the essence of particular artists or their pieces. I fear, however, that it will be spectacularly good at giving that impression, in the same way that Chat-GPT seems to reason, and that with it the economic incentive will move significantly away from human-created art.
- See page 33 et seq. of the aforementioned Autoría y Autoencoders by Santiago Caruso.
- In the words of attorney Matther Butterick.
- Debate of which the aforementioned article Fair Learning is a convincing example.
- Not only its legality per se, but also the technical consequences it entails.
- As it is explained in this article, can be cheked hereand should not be ignored in view of its impact on the fair use analysis the fair use doctrine.
- Of which the cases Github, Getty Imagesor the legal controversy with LAION in Europe are fantastic examples.
- Such as compensation for data used by training AIs requested by platforms like Reddit and Stack OverflowThe use of watermarking, or the transition of graphic art to a "Pay per Play" model like that of music, or even (God forbid) the creation of new collective management entities.
Leave a Reply