


Footnotes
- Como se puede comprobar en este enlace, 9.268 obras gráficas del Sr. Kinkade constan en la base de datos LAION, utilizada para el entrenamiento del modelo de IA Stable Diffusion.
- La huelga de la Writers Guild of America y el manifiesto de EGAIR son buenos ejemplos de ello.
- Terminológicamente, utilizamos “modelo de IA” cuando nos queremos referir al back-end, es decir, al motor de la IA. Por otro lado, utilizamos “sistema de IA” cuando nos queremos referir a todo el aplicativo. Esta diferencia queda clara en la redacción del artículo 10.6 del AI ACT, que emplea ambos términos en este sentido.
- Tal y como explica el artículo “What exactly is Machine Learning?”
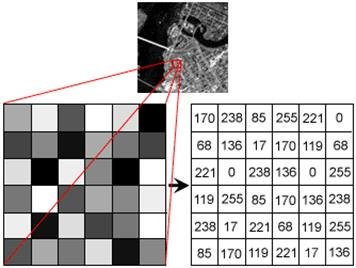
- Figura extraída de aquí. Como es evidente, el proceso es muchísimo más complejo que el ejemplo.
- Estrictamente hablando, cuando se calcula el error de un solo output estaríamos hablando de la función de pérdida, que pasa a ser la función de costo cuando lo que expresa es el error promedio del conjunto del entrenamiento realizado.
- Teniendo en cuenta que los valores del modelo de IA empiezan siendo aleatorios.
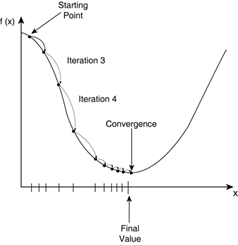
- Gráfico obtenido de este sitio web.
- Titulados “But what is a neural network? | Chapter 1, Deep learning” y “Gradient descent, how neural networks learn | Chapter 2, Deep learning” ambos del canal “3Blue1Brown”.
- Ver definición de ‘razonar’ de la RAE.
- Como explican los artículos “What Is Stable Diffusion and How Does It Work?” y “How does Stable Diffusion work?” con mayor detalle técnico.
- Un concepto de elevadísima complejidad, explicado en el artículo “What Is the Latent Space of an Image Synthesis System?”
- Imagen del ya citado artículo “How does Stable Diffusion work?”.
- Gif extraído de Reddit, Here's a short video of what happens behind the scenes when Stable Diffusion generates a picture.
- Aunque quizás no sea del todo exacto, es un concepto entendedor. Para más, véanse los artículos “How ChatGPT Works: The Model Behind The Bot” y “How ChatGPT actually works”.
- No estamos tampoco ante la panacea. Véase el artículo (bastante desfasado pero no por ello desdeñable) “How to Systematically Fool an Image Recognition Neural Network” sobre cómo engañar un sistema como el descrito.
- A favor, y explicándolo mejor que nosotros el excelente paper “Fair Learning”. En contra, en Stable Diffusion litigation se argumenta que el output debe considerarse una obra derivada de las obras utilizadas para entrenar el modelo. Basta por ahora con apuntar que plantear que una determinada obra generada por un modelo de IA es una derivación de las obras precedentes con las que se ha entrenado dicho modelo (que perfectamente pueden ser más de un millón incluso para las imágenes menos populares) es desvirtuar el concepto de obra derivada.
- Titulado “Generative AI, Copyright and the AI Act” por João Pedro Quintais.
- En el apartado 62 de la STJUE “Infopaq I” (ECLI:EU:C:2009:465), al respecto de la provisionalidad de la reproducción, se sostiene: “La seguridad jurídica de los titulares de los derechos de propiedad intelectual exige además que la conservación y supresión de la reproducción no dependa de un acto humano discrecional, concretamente la intervención del usuario de las obras protegidas por dicha normativa. Ciertamente, en tal caso, nada garantiza que el usuario procederá a la supresión efectiva de la reproducción o, en todo caso, que lo suprimirá cuando ya no se pueda justificar su utilidad en el marco del procedimiento técnico.” Por lo que, si fuese automática la supresión de las obras originales al ser sustituidas por patrones (de hecho, debería serlo, por carecer los modelos de IA de la suficiente memoria como para almacenar las imágenes originales) se debe considerar que su uso es provisional.
- Algo extremadamente relevante a la vista del apartado 65 de la ya citada STJUE Infopaq I. Es decir, que si el propietario de una IA decide mantener un repositorio con las obras que ha utilizado para entrenar la IA por cualquier motivo (trazabilidad del sistema, protección de datos, gestión de derechos de imagen, revisiones sobre sesgos del modelo, etc.) dejará de aplicarle la excepción. Parece que, indeseablemente, se penaliza una buena práctica como esta en el entrenamiento de modelos de IA. Asimismo, el Tribunal Supremo ha puesto el énfasis en esta cuestión en la Sentencia 650/2022 de 11 de octubre (ECLI:ES:TS:2022:3598): “la demandada debería haber justificado que la reproducción de esos fonogramas encaminada a su comunicación pública formaba parte de un proceso tecnológico que aseguraba el carácter provisional y transitorio de la reproducción por medio de un mecanismo automatizado que, tanto en su creación como supresión, no requiere la intervención humana.”
- STJUE “Stichting Brein” C-527/15 de 26 de abril de 2017 (ECLI:EU:C:2017:300).
- Sentencia de 4 de octubre de 2011, Football Association Premier League y otros, C‑403/08 y C‑429/08, EU:C:2011:631, § 170-172.
- En sentido contrario, resulta de aplicación la STJUE “Ryanair” Asunto C-30/14 ECLI:EU:C:2015:10, ya que al ser el contenido objeto del scraping protegible por derecho de autor, al propio scraping le resultarán de aplicación las excepciones de la Directiva Infosoc que precisamente ahora analizamos. Para contextualizar, el scraping es algo que Google hace con regularidad para tener indexado todo el contenido de internet posible en su buscador, al que accederá salvo que el titular del web haga “opt-out” con medidas tecnológicas.
- Pablo Fernández Carballo-Calero, en su obra de referencia “La propiedad intelectual de las obras creadas por inteligencia artificial” analiza si la propiedad intelectual debería incentivar el contenido generado por una IA sin intervención humana en función de las teorías 1) Del trabajo (Locke) 2) Personalista y 3) Utilitarista. La conclusión alcanzada es que el espíritu del derecho de autor no debería conducirnos a reconocer como obras aquellas creadas sin intervención humana. Sin embargo, ello no significa que dicha generación una actividad ilícita, sino que sencillamente no debería incentivarse por la vía de la propiedad intelectual.
- Se me están acabando las formas de decir “muchos, muchísimos datos”.
- Este análisis se hace sin perder de vista que el TJUE, en Infopaq II, apartados 55-57 dice: “basta señalar que cuando dichos actos de reproducción cumplen todos los requisitos del artículo 5, apartado 1, de la Directiva 2001/29, tal como han sido interpretados por la jurisprudencia del Tribunal de Justicia, debe considerarse que no entran en conflicto con la explotación normal de la obra ni perjudican injustificadamente los intereses legítimos del titular del derecho”. A pesar de la contundencia de las palabras del TJUE esta conclusión no parece aplicable sin mayor reflexión a los casos de ML.
- Traducido burdamente al castellano desde este enlace: “Está permitida la explotación de una obra, de cualquier forma y en la medida que se considere necesaria, en cualquiera de los siguientes casos, o en cualquier otro caso en el que no sea el propósito de una persona disfrutar personalmente o hacer que otra persona disfrute de los pensamientos o sentimientos expresados en dicha obra; sin embargo, esto no se aplica si la acción perjudica injustificadamente los intereses del titular de los derechos de autor a la luz de la naturaleza o el propósito de la obra o de las circunstancias de su explotación: (i) si se realiza para su uso en pruebas para desarrollar o poner en uso práctico tecnología relacionada con la grabación de sonidos o imágenes de una obra u otra explotación de este tipo; (ii) si se realiza para su uso en análisis de datos (entendiendo por ello la extracción, comparación, clasificación u otro análisis estadístico del lenguaje, sonidos, imágenes u otros datos elementales constitutivos de un gran número de obras o de un gran volumen de otros datos de este tipo; lo mismo se aplica en el artículo 47-5, apartado (1), inciso (ii)); y (iii) si se explota en el curso del tratamiento informático de datos o se explota de otro modo que no implique que lo expresado en la obra sea percibido por los sentidos humanos (para las obras de programación informática, dicha explotación excluye la ejecución de la obra en un ordenador), más allá de lo establecido en los dos puntos anteriores".
- En este sentido, el fantástico artículo: Text and data mining exceptions in the development of generative AI models: What the EU member states could learn from the Japanese “nonenjoyment” purposes? de Artha Dermawan.
- Como describe Ryan Khurana en este enlace y podemos comprobar en el apartado 2 de los Términos de uso de Open AI, entre otros.
- Tal y como elocuentemente se describe en “Fair Learning”: “Y como es probable que los conjuntos de formación contengan millones de obras diferentes con miles de propietarios distintos, no hay ninguna opción plausible que consista simplemente en licenciar todas las fotografías, vídeos, archivos de audio o textos subyacentes para el nuevo uso. Así que permitir una reclamación de derechos de autor equivale a decir, no que se pagará a los propietarios de los derechos de autor, sino que no se permitirá el uso en absoluto, al menos sin intervención legislativa” (Traducción no oficial).
- Como le sucedió al programador Tim Davis, de lo que se quejó en Twitter.
- Como cuando un sistema de IA produce output que incluye personajes protegidos por el derecho de autor, como en este caso. Hablamos de obra derivada porque de forma evidente se está transformando la obra original. Sin embargo, esta es la excepción a la regla general, ya que como hemos visto, la generación de contenido no se basa directamente en una o varias obras previas, sino en millones de ellas, siendo imperceptible la influencia de cada una en el resultado final.
- Creo que no peco de romántico al pensar que un modelo de IA nunca va a poder capturar fielmente la esencia de determinados artistas o sus piezas. Temo, sin embargo, que será espectacularmente buena en dar esa impresión, de la misma forma que Chat-GPT parece razonar, y que con ello el incentivo económico se aleje significativamente del arte creado por humanos.
- Ver página 33 y ss. del ya citado Autoría y Autoencoders de Santiago Caruso.
- En palabras del abogado Matther Butterick.
- Debate del que el citado artículo Fair Learning es un convincente ejemplo.
- No solo su legalidad per se, sino también las consecuencias técnicas que trae aparejadas.
- Como se explica en este artículo, se demuestra aquí, y no debe ignorarse teniendo en cuenta su incidencia en el análisis del fair use.
- De las que los casos Github, Getty Images, o la controversia jurídica con LAION en Europa son fantásticos ejemplos.
- Tales como una compensación por los datos usados por entrenar IAs solicitado por plataformas como Reddit y Stack Overflow, el uso de marcas de agua, o la transición del arte gráfico a un modelo como el de la música de “Pay per Play”, o incluso (Dios nos libre) la creación de nuevas entidades de gestión colectiva.
Deja una respuesta